



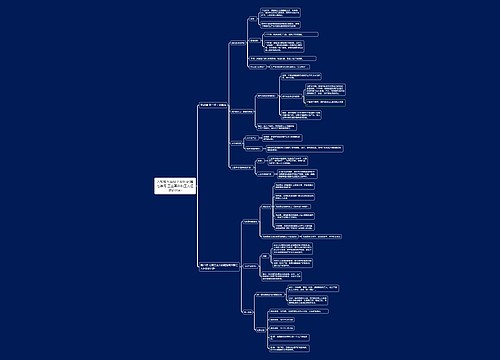
第三章 网页解析基础思维导图

网页基础,数据库,数据存储等内容讲解
树图思维导图提供 第三章 网页解析基础 在线思维导图免费制作,点击“编辑”按钮,可对 第三章 网页解析基础 进行在线思维导图编辑,本思维导图属于思维导图模板主题,文件编号是:44db076f04b9c64fbfbfdaf9f99cd3ba
思维导图大纲
第三章 网页解析基础思维导图模板大纲
网页基础
1.HTML
网页一般由 HTML、CSS 和JavaScript 三部分组成,其中 HTML 用于定义网页的结构和内容:CSS用于定义网页的样式;JavaScript 用于定义网页的行为。
超文本标记语言(Hyper Text Marked Language,HTML)是一种用来描述网页的语言它通过不同类型的标签来描述不同的元素,各种标签通过不同的排列和嵌套形成网页的框架。
有的标签还带有属性参数,其语法格式如下: <标签 属性="参数值">
2.HTML DOM
文档对象模型 (Document Object Model,DOM)定义了访问 HTML 和可扩展标记语言(Extensible Markup Language,XML)文档的标准。HTML DOM 将HTML 文档呈现为带有元素、属性和文本的树结构(也称为节点树)。
在节点树中,顶端节点称为根(root),除了根节点外,其他每个节点都有父节点(parent),同时可拥有任意数量的子节点 (child) 和兄弟节点(sibling)。
3.CSS 选择器
层叠祥式表(Cascading Style Sheets,CSS) 选择器可以定位节点。
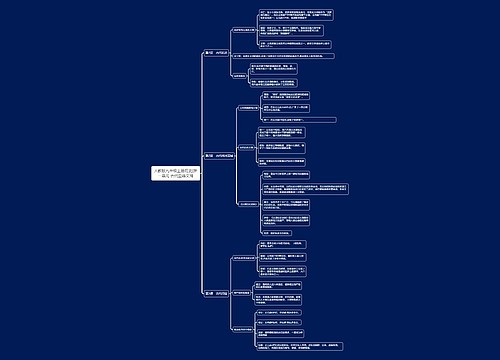
lxml库
lxml库简介
Ixml 库是 Python 的一个网页解析库,支持HTML 和XML 的解析,支持XPath 解析方式,解析效率非常高。lxml 库不是 Python 内置的标准库,使用之前需要安装。
lxml库的大部分功能是由 etree 模块提供的。使用XPath 解网页时,首先需要调用etree 模块下的 HTML类对 HTTP 响应的网页进行初始化 (etree.HTMLO),从而构造一个Element 类型的XPath 解析对象;然后使用XPath 对 Element 对象进行节点选择,最后返回一个列表。若 HTML 中的节点没有闭合,etree 模块还可提供自动补全功能。
XPath语法
XPath 的选择功能十分强大,它提供了非常简明的路径选择表达式。另外,它还提供了超过 100 个内建函数,用于字符串、数值、时间的匹配及节点、序列的处理等。可以说,几乎所有想要定位的节点都可以用XPath 来选择。
1.通过路径选择节点
HTML源代码是层次结构的,如果想要选择一个节点,可以一层一层往下查找。XPath实际上就是使用这种层次结构的路径来找到相应的节点,它类似于人们日常使用的地址,它们都是从大的范围一直缩小到具体的某个地址。XPath 通过路径选择节点常用的语法。
2.通过属性选择节点
XPath 可以通过节点的属性来选择包含某个指定属性值的节点。它可在仅掌握节点部分特征的情况下,利用模糊搜索函数选择节点。
3.提取文本
解析网页的目的是通过选择节点来提取节点文本或属性值,从而获取所需的信息。
beautifulsoup4库
beautifulsoup4库简介
beautifulsoup4 库也称为 Beautiful Soup 库或 bs4 库,用于解 HTML或XML文档beautifulsoup4 库不是 Python 内置的标准库,使用之前需要安装。
beautifulsoup4基本用法
beautifulsoup4 库中最重要的是 BeautifulSoup 类,它的实例化对象相当于一个页面。解析网页时,需要使用 BeautifulSoup()创建一个BeautifulSoup 对象,该对象是一个树形结构,包含了 HTML 页面中的标签元素,如<head>、<body>等。也就是说,HTML 中的主要结构都变成了 BeautifulSoup 对象的一个个属性,然后可通过“对象名.属性名”形式获取该对象的第一个属性值 (即节点)。
每一个HTML 标签在 beautifulsoup4 库中又是一个对象,称为 Tag 对象,它有4个常用属性.
1.name:标签的名字,如 head、title 等,返回一个字符串 2.string:标签所包围的文字,网页中真实的文字 (尖括号之间的内容),返回一个字符串 3.attrs:字典,包含了页面标签的所有属性(尖括号内的所有项),如 href,返回一个字典 4.contents:这个标签下所有子标签的内容,返回一个列表
其中,attrs 返回的是标签的所有属性组成的字典类型的数据,可通过“atrrs[属性名]”形式获取属性值。
方法选择器
beautifulsoup4 库还提供了一些查询方法,如 find all0和 find0等find al10方法会遍历整个 HTML 文件,按照条件返回所有匹配的节点,其方法原型如下:
find all(name, attrs, recursive,string, limit)
(1)name:通过HTML 标签名直接查找节点。 (2)attrs: 通过 HTML 标签的属性查找节点(需列出属性名和值),可以同时设置多个属性。 (3)recursive: 搜索层次,默认查找当前标签的所有子孙节点,如果只查找标签的子节点,可以使用参数 recursive = False。 (4)string: 通过关键字检索 string 属性内容,传入的形式可以是字符串,也可以是正则表达式对象。 (5)limit:返回结果的个数,默认返回全部结果。
简单地说,BeautifulSoup 对象的 find all0方法可以根据标签名、标签属性和内容,查找并返回节点列表。
CSS选择器
beautifulsoup4库还提供了使用 CSS 选择器来选择节点的方法(只需要调用 select0方法传入相应的 CSS 选择器即可)。
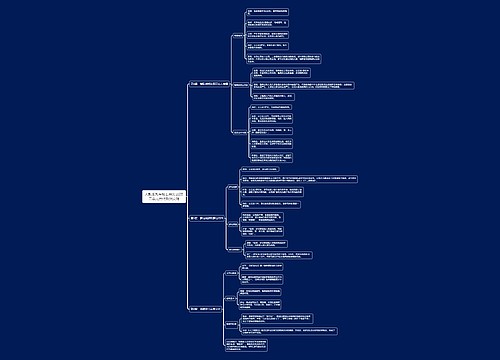
正则表达式
正则表达式基础
正则表达式是用于处理字符串的强大工具,它使用预定义的特定模式去匹配一类具有共同特征的字符串,主要用于快速、准确地完成复杂字符串的查找、替换等。
具体应用时,可以单独使用某种类型的元字符,但处理复杂字符串时,经常需要将多个正则表达式元字符进行组合。下面给出了几个示例。
(1)[a-zA-Z0-9]可以匹配一个任意大小写字母或数字 (2)(w)16,153$匹配长度为 6~15 的字符串,可以包含数字、字母和下划线(3)w+@(w+)+w+s检查给定字符串是否为合法电子邮件地址。 (4)'d1,3;\d1,3]d1,3d1,33s 检查给定字符串是否为合法P 地址。
re模块
函数参数 pattern 为正则表达式;参数 string 为字符串;参数 flags 的值可以是re.I(忽略大小写)、re.M(多行匹配模式)和 re.S(匹配包含换行符在内的所有字符)等。
存储数据至文件
存储数据至JSON文件
JavaScript 对象标记 (Javascript Object Notation,JSON)是一种轻量级的文本数据交换格式。它通过对象和数组的组合来表示数据,构造简洁但是结构化程度非常高。Python提供了json 库来实现对JSON 文件的读写操作。json 库是 Python 内置的标准库,不需要额外安装即可使用。
1.写入 JSON 文件
利用 dumps0方法可以将 Python数据类型转化为JSON格式的字符串,然后调用文件的write0方法写入文本。
dumps0方法原型如下: dumps(objskipkeys=False,ensure ascii=Truecheck circular=True,allow nan=True,cls=None,indent=None,separators=Nonedefault-None,sort keys=False,**kw)
1.obj: Python 数据序列。
2.skipkeys: 表示是否跳过非 Python 基本类型的键,默认值为 False,设置为 True时,表示跳过此类键。
3.ensure _ascii: 表示显示格式,默认为 True,如果需要输出中文字符,需要将这个参数设置为 False,并在写入文件时规定文件输出的编码。
4.indent: 表示输出时缩进字符的个数。
5.sort keys:表示是否根据键的值进行排序,默认为 False,设置为 True 时数据将根据键的值进行排序。
2.读取 JSON 文件
利用 loads()方法可以将JSON 格式的字符串转化为 Python 数据类型,如果从JSON文件中读取内容,可以先调用文件的 read()方法读取文本内容,然后再进行转换。
存储数据至CSV文件
字符分隔符(Comma-Separated Values,CSV) 也称号分隔符,其文件以纯文本形式存储表格数据。CSV 文件由任意数目的记录组成,记录间以某种换行符分隔;每条记录由字段组成,字段间的分隔符是其他字符或字符串,最常见的是逗号或制表符。通常,所有记录都有完全相同的字段序列,结构简单清晰。Python 提供了 csv 库来实现 CSV 文件的读写操作。csv 库是Python 内置的标准库,不需要额外安装即可使用。
1.写入 CSV 文件
csv 库提供了初始化写入对象的 writer()方法,还提供了 writerow()方法(写入一行)和 writerows()方法(写入多行) 用于写入文件。
2.读取 CSV 文件
读取 CSV 文件时,可通过调用 reader0)方法返回一个可迭代对象,此对象只能选代一次,不能直接输出,须调用 list0方法将其转换为列表输出。
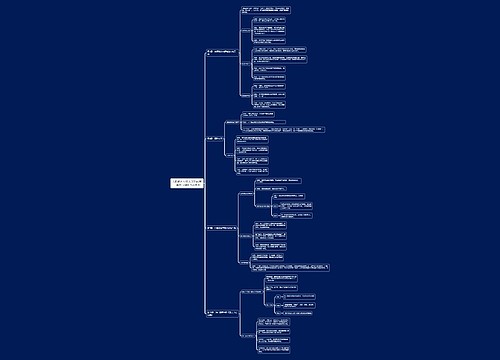
本章小结
1.lxml库是 Python 的一个网页解析库,支持HTML和XML的解析,支持XPath解析方式。
2.XPath 按照语法可通过路径和属性选择节点,并提取文本和属性
3.beautifulsoup4 库中 Tag 对象的四个属性包括 name、string、attrs 和 contents。
4. beautifulsoup4 库常通过 find all0方法和 select0方法选择节点。
5.正则表达式使用预定义的特定模式去匹配一类具有共同特征的字符串
6.Python 使用re 模块来实现正则表达式的操作。
7.json 库通过 dumps0方法和 loads0方法写入和读取JSON 文件
8.csv 库通过创建 writer 和 reader 对象写入和读取 CSV 文件。
相关思维导图模板


树图思维导图提供 中国共产党纪律处分条例 - 第三章 纪律处分运用规则 在线思维导图免费制作,点击“编辑”按钮,可对 中国共产党纪律处分条例 - 第三章 纪律处分运用规则 进行在线思维导图编辑,本思维导图属于思维导图模板主题,文件编号是:9f6406f5cafd1e0b82b6b199db746b48


树图思维导图提供 涉税风险解析与实操训练 在线思维导图免费制作,点击“编辑”按钮,可对 涉税风险解析与实操训练 进行在线思维导图编辑,本思维导图属于思维导图模板主题,文件编号是:4ff52bab97ccddd8b15b2014afccb2c5





 上海工商
上海工商