



第七章 Spark GraphX——图计算框架思维导图

图计算框架介绍
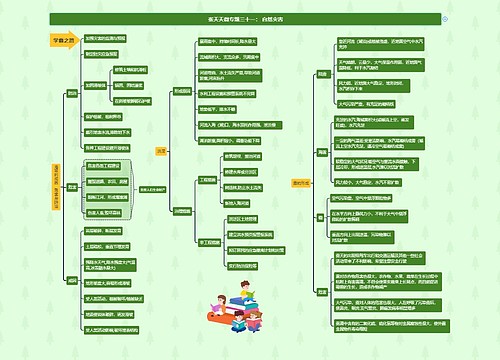
树图思维导图提供 第七章 Spark GraphX——图计算框架 在线思维导图免费制作,点击“编辑”按钮,可对 第七章 Spark GraphX——图计算框架 进行在线思维导图编辑,本思维导图属于思维导图模板主题,文件编号是:3eef241ee87485bc29f6dcbb9e23b037
思维导图大纲
第七章 Spark GraphX——图计算框架思维导图模板大纲
图的基本概念
此处介绍的图(Graph)不是指图片,而是数据结构中的图结构类型。图是由一个有穷非空顶点集合和一个描述顶点之间多对多关系的边集合组成的数据结构。图的结构通常表示为 G(V,E)。其中,G 表示一个图,V 是图 G 中顶点的集合,E 是图 G 中边的集合。图是一种数据元素间有多对多关系的数据结构,加上一组基本操作构成的抽象数据类型。图是一种复杂的非线性结构,在图结构中,每个元素都可以有0个或多个前驱,也可以有0个或多个后继,即元素之间的关系是任意的。图的每个顶点都代表了一个重要的对象,每一条边则代表了两个对象之间的关系。 图按照边无方向和有方向可以分为有向图和无向图。有向图是由顶点和弧(有向边)构成的,无向图是由顶点和无向边构成的,如图7-1所示。如果任意两个顶点之间都存在边那么该图称为完全图,其中边都有方向的图称为有向完全图。如果无重复的边或顶点到自身的边那么该图称为简单图。
图计算的应用
图论(Graph Theory)是数学的一个分支,以图为研究对象。而图计算是指以“图论’为基础的对现实世界的采用图结构的抽象表达以及在图数据结构上进行的计算模式。图数据结构很好地表达了数据之间的关联性,而关联性计算是大数据计算的核心,通过获得数据的关联性,可以从噪声很多的海量数据中抽取有用的信息。
GraphX 的基础概念
Spark 的每一个子框架都有一种抽象数据结构,Spark GraphX框架的核心抽象数据结构是弹性分布式属性图(Resilient Distribute Property Graph,简称 Graph )。Graph 是一种顶点和边都带属性的有向多重图,同时拥有 Table和 Graph 两种视图,但只需要进行一次物理存储。两种视图都有自带的操作符,使用图计算的操作很灵活,执行效率 Spark GraphX 是一个基于 Spark 的分布式图计算框架,提供了众多图计算和图挖掘的很高。操作接口,简洁易用。GraphX的分布式或并行处理指的是将图拆分成很多子图,再分别对子图进行计算,计算时可以分别迭代进行分阶段计算。SparkGraphx中包含对图的一系列操作方法(如 subgraph()、joinvertices()和 aggregatemessages()等方法)以及优化的 Prege操作接口。
GraphX 的发展历程
0.5 版本时,在 Spark 中自带了一个小型的 Bagel模块,即图计算引擎,但该版本非常原始,性能比较弱,属于实验型产品。 到 0.8 版本时,鉴于各行业对分布式图计算的需求日益增长,Spark 开始独立出一个分支GraphX作为图计算模块。借鉴基于图像处理模型的图计算框架 GraphLab,开始设计开发 GraphX。0.9版本时,GraphX 模块被正式集成至 Spark 的主干,虽然是 Alpha 版本,但是已可以试用,Bagel 正式告别舞台。 1.0版本,GraphX 正式投人生产使用。 在 1.1 版本中,GraphX 对边的表示,从 EdgeRDD[ED]类型转换为 EdgeRDD[ED,VD类型,并进行了缓存优化。 在 1.2 版本中,GraphX 引人了新的图聚合操作 aggregatemessages,用于替换原本的mapReduceTriplets 操作。 Graphx 目前依然处于快速发展中,从 0.8 版本到 0.9版本再到 1.2 版本,每个版本的代码都有不少的改进和重构。虽然和 GraphLab 的性能还有一定差距,但凭借 Spark 的一体化流水线处理、社区的高活跃度和 Spark 快速改进的速度,GraphX 目前依旧具有强大的竞争力。
GraphX 常用 API
创建与存储图
GraphX 对 Spak RDD 进行了封装,用类表示图模型,并提供了一些基础的图计算的方法帮助了解图的基本结构和操作,实现图计算。
GraphX中一些专业名称解释说明如下 (1)Edge:边对象,Edge(srcId,dstId,attr),存有 srcId、dstId、attr3 个参数,以及一些操作边的方法。 (2)RDD[Edge]:存放边对象的 RDD。 (3)EdgeRDD:提供边的各种方法的对象。 (4)RDD[(Vertexld,VD)]:存放顶点的 RDD,顶点有 VertexId 和 VD 两个参数,第个表示顶点 ID,第二个表示顶点属性。 (5)VertexRDD:提供顶点的各种方法的对象。EdgeRDD与RDD[Edge]之间、VertexRDD与 RDD[(VertexId,VD)]之间的继承关系如下:EdgeRDD 继承 RDD[Edge]。 VertexRDD[VD]继承 RDD[(VertexId,VD)]
图的创建
图的创建是进行图计算的重要步骤。在 Spark Graphx 中创建图的方式很多,根据不同的数据集可以使用不同的方法。GraphX有一个 Graph类,对 Graph 类进行实例化可得到个 Graph 对象。Graph 对象是用户的操作人口,包含边属性、顶点属性、创建图的方法查询的方法和其他转换的方法等。 在 HDFS 中有两个数据文件,一份为用户信息数据 vertices.txt,有3个字段,分别为用户D、姓名和职业。另一份为是用户之间的关系数据 edges.txt,有3个字段,1、2个是用户 ,第3个是第1个用户与第2个用户的关系,“37Collaborator”表示3是7的合作伙伴。
vertices.txt 作为顶点数据,用户 ID 为顶点 I,其他为顶点属性。edges.txt 作为边数据,包含起点用户 ID、目标点用户 ID、边属性3个字段。根据顶点数据和边数据,构建图 7-3 所示的用户关系网络图。顶点数据包含用户 D 和用户属性,边数据包含起点和目标点,并且有边属性和指向。例如,5 指向3.属性“Advisor”表示的是用户5是用户3的顾间。 在 Spark GraphX 中进行图计算操作时,需要先导人指定的包,其中,org.apache.spark.graphx 包中包含图计算所需要的类。
创建图的方法主要有3种,适用于不同类型的输入数据。
创建图的方法解释说明如下。 (1)根据有属性的顶点和边构建图(GraphO) 使用 Graph()方法构造图时,默认使用 GraphX的 apply()方法。Graph()方法有以下3个参数。 ① vertices:RDD[(VertexId,VD)]:“顶点”类型的 RDD,其中 Vertexld 为顶点 ID(其类型必须为 Long 类型 ),VD 为顶点属性信息。 ② edges:RDD[Edge[ED]]:“边”类型的 RDD,Edge 类包含 srcId(起点,Long 类型)dstld(目标点,Long类型)、attr(边属性)3个参数。 ③ defaultVertexAttr:一个固定的顶点信息,数据中出现顶点缺失情况时使用。在这3个参数中,必须设置前两个参数,最后一个参数则为可选项。“顶点”和“边”类型的 RDD 来自不同的数据源,因此需要一份顶点数据文件和一份边数据文件。根据表7-3 所示的顶点数据和表 7-4所示的边数据创建图,首先创建“顶点”类型的 RDD 和“边”类型的 RDD,再利用两个 RDD 创建图。在后续 GraphX 常用操作方法的介绍中,如果没有特别指明,那么均以该图为例。
(2)根据边创建图(Graph.fromEdges0)) Graph.fromEdges()方法使用起来比较简单,仅由“边”类型 RDD 建立图,没有边的属性则将其设置为一个固定值,“边”中出现的所有顶点(起点、目标点)作为图的顶点集,顶点属性将被设置为默认值。fomEdges0方法有以下两个参数值。① RDD[Edge[ED]]:“边”类型的 RDD。 ②)defaultValue:VD:默认顶点属性值。 根据边创建图只需要用到边数据。仅根据edges.txt中的边数据创建图,顶点由边数据中出现的顶点决定。
(3)根据边的两个顶点的二元组创建图(Graph.fromEdgeTuples())Graph.fomEdgeTuples()方法与 Graph.fromEdges()方法类似,均是通过边数据创建图的。不同的是,Graph.fomEdges()方法是通过“边”类型的 RDD 创建图的,有边属性。而Graph.fromEdgeTuples()方法是通过边的两个顶点的顶点 D 组成的二元组创建图的,不包括边属性,将一条边的起点与目标点放在一个二元组中,通过边的二元组 RDD 创建图。Graph.fromEdgeTuples(方法有以下3个输人参数。① rawEdges:RDD[(VertexId,VertexId)]:其中的数据是由起点与目标点组成的元组 ② defaultValue:vD:默认顶点属性值。 ③ uniqueEdges: Option[PartitionStrategy]=None:是否对边进行分区的选项,默认不分区Graph.fromEdgeTuples()方法仅需要边的起点和目标点。将 edges.txt 文件的数据作为 输入数据,通过 Graph.fromEdgeTuples()方法创建图。
图的缓存及释放
在图计算的过程中,如果频繁使用一个图,为了节省重新计算的时间,需要对图进行缓存。
(1)图的缓存 在 Spark 中,RDD默认没有持久化在内存中。多次使用某个变量时,为了避免重复计算,变量必须被明确缓存,GraphX中的图也使用相同的方式。当一个图需要多次计算或使用时,需要对图进行缓存,这样在多次调用图时则不需要进行重复计算,可以提高运行效率。缓存有 cache0)和 persist()两种方法,与第4章中RDD的持久化类似。对于 persist()方法,如果指定缓存类型,需要导人 org.apache.spark.storage.StorageLevel类。指定缓存位置为内存时,写人的参数为 StorageLeve1.MEMORY ONLY。
(2)释放缓存 在迭代过程中,释放缓存也是必要的。默认情况下,虽然缓存在内存中的图会在内存紧张时被强制清理,但是在运算过程中还是会影响垃圾回收和数据处理的速度。因此可以释放已经完成计算且无须再使用的图的缓存,也可以释放在迭代过程中无须再使用的图的缓存。释放缓存的方法有以下3种。 ① Graph.unpersist(blocking=true):释放整个图的缓存。 ② Graph.unpersistVertices(blocking=true):释放内存中缓存的顶点,适用于只修改顶点的属性值,但会重复使用边进行计算的迭代操作,使用该方法可以释放先前迭代的顶点属性,提高垃圾回收性能。 ③ Graph.edges.unpersist(blocking=true):释放边缓存,适合对边进行修改,但会重复使用点击运算操作。
查询与转换数据
图的基本操作对应方法均被定义在 Graph 类中,除了创建图的方法外,还包括数据查询、数据转换操作的常用方法,通过 Graph 类所定义的方法可以完成基本的图计算,具体的数据查询与转换的方法介绍如下。
1.数据查询 对基于代码 建立的用户关系网络图进行査询。查询内容包括顶点与边的数量、顶点与边的视图、出度数(以当前顶点为起点的边的数量)和入度数(以当前顶点为目标点的边的数量)。
(1)顶点查询和边查询 ① numVertices:査询图中顶点个数,不需要输人任何参数,直接通过 Graph.numVertices查询,返回类型为 Long类型。 ② numEdges:查询图中边的数量,不需要输人任何参数,直接通过 Graph.numEdges查询,返回类型为 Long 类型。
(2)视图操作 Spark GraphX中有3种基本视图可以访问,包括顶点视图(Vertices )、边视图(Edges)和整体视图( Triplets )。假设有一个 Graph 的实例 graph,通过 graph.vertices、graph.edges、graph.triplets 即可访问 3 种视图。 ① 顶点视图。顶点视图可以査看顶点的信息,包括顶点 ID 和顶点属性。有两种方式可以查看顶点信息。通过 graph.vertices 可以返回 VertexRDD[VD]类型的数据,VD 为顶点属性,继承于 RDD[(VertexID,VD)],因此也可以使用 Scala 的 case 表达式解构元组,查看顶点信息。 Vertices 返回的 RDD[(VertexID,(String,String))]通过 case 解构,再通过 map()方法将属性部分的值调换,过滤顶点 ID 后输出结果。 ② 边视图。边视图只返回边的信息,包括起始点 ID、目标点 ID 和边属性。graph.edges返回一个包含 Edge[ED]对象的 EdgeRDD,ED 表示边属性的类型。Edge有3个字段,即起点 DD、目标点 I 和边属性,并且可以通过 case 类的类型构造器匹配并返回 EdgeRDD,下面分别介绍查询方式。 ③ 顶点与边的三元组整体视图。三元组整体视图逻辑上将顶点和边的属性保存为一个RDD[EdgeTriplet[VD,ED]],包含 EdgeTriplet 类的实例。EdgeTriplet 类继承于 Edge 类,因此可以直接访问 Edge 类的3个属性,并且加入了 srcAtr 和 dstAtt 成员,这两个成员分别包含起点和目标点的属性。graph.triplets 可以用于查看边和顶点的所有信息,是一个完整的视图。
(3)度分布计算 度分布是图计算中一个非常基础、非常重要的指标。度分布检测的目的,主要是了解 图中“超级节点”的个数和规模,以及所有节点度的分布曲线。超级节点的存在对各种传播算法都会有重大的影响(不论是正面的助力还是反面的阻力),需要预先对这些数据进行估计。借助 GraphX基本的图信息接口 degrees:VertexRDD[Int](包括inDegrees 和outDegrees可以计算度分布,并进行各种各样的统计。Graph类中度分布计算的方法主要有以下3个。 ① degrees:返回每个顶点的度数,不需要参数。graph.degrees 返回的是 VertexRDD[Int]类型,即(VertexID,Int),元组的第一个元素为计算度数的顶点,第二个元素为该顶点的度数。 ② inDegrees:计算每个顶点的入度数,不需要参数。 ③ outDegrees:计算每个顶点的出度数,不需要参数。查询用户关系网络图中每个顶点的总度数,即入度数和出度数。
用户如果想要对图的度进行一些特别的计算,如求最大值、最小值和平均值等,那么可以通过 RDD 内置的方法完成。例如,使用RDD 内置的 min()、max()、sortByKey()、top()等方法对度统计最大值和最小值、排序、取出度数排在前N位的顶点。graph.degrees 返回的是 VertexRDD[Int],即(VertexID,Int),需要将其转换成 RDD[(IntVetexId)],因为这些方法都是对第一个值,也就是 Key 进行操作的。求度最大值、最小值以及降序排序后度数排在前3的顶点。
2.数据转换 转换数据操作的重要特征是,允许所得图形重用原有图形的结构索引,即还能保存图的结构。
(1)mapVertices() 通过 mapVertices()方法直接对顶点进行 map操作,返回一个改变图中顶点属性的值或类型之后的新图。mapVertices()方法需要一个函数调用 Spark 中的 map 操作,更新顶点的属性值,顶点的属性可以由 VD 类型转变为一个新的类型。例如,用户关系网络图中顶点有两个属性值,通过 mapVertices()方法只取第一个值(姓名)作为属性值。
(2)mapEdges() 通过 mapEdges()方法直接对边的属性进行操作,调用 Spark 中的 map 操作更新边的属性值,需要一个修改边属性的函数,map 遍历的每一个元素都是“边”类型的,结果返回个修改了图中边属性的值或类型之后的新图。
(3)mapTriplets() mapTriplets()方法针对边的属性值调用 Spark 中的 map 操作,通过一个修改边属性的函数更新边的属性值,结果返回一个修改了图中边属性的值或类型之后的新图。与 mapEdges()方法不同的是,mapTriplets()方法的每一个元素是一个包含顶点属性和边属性的三元组,因此可以使用顶点的属性。
转换结构与关联聚合数据
转换结构
在 GraphX中,除了基础的图计算的方法,还可以对图的结构进行转换对数据进行关联聚合。图结构的转换和图数据的关联聚合在图计算中也是非常重要的操作,在解决实际问题的过程中常常会被用到。
1.结构转换 结构转换是指对整个图的结构进行操作,生成新的图。在 Spark GraphX中图结构转换操作的方法也是存放在Graph类中的。
(1)reverse 方法将返回一个新的图,图的边的方向与原图相比都是反转的。没有修改顶点或边的属性,也没有改变边的数量,不需要输人其他参数。
(2)subgraph()方法是创建子图的方法。子图是指节点集和边集分别是某一图的节点集的子集和边集的子集的图。subgraph(方法可以用于很多场景,如获取感兴趣的顶点和边组成的图,或获取清除断开的链接后的图。在 subgraph()方法中需要输人边的过滤条件或顶点的过滤条件,设置了顶点的过滤条件即可查询出满足过滤条件的顶点组成的图,设置边过滤条件即可查询出满足条件的边组成的图。如果顶点和边的过滤条件均被设置,即可查询 出满足过滤条件的顶点和边组成的图。对边和顶点同时过滤时,用“,”隔开边和顶点的过滤条件。如查询用户社交网络图中追随者支持度大于 3、用户年龄大于 30的顶点和边组成的子图,顶点操作通过一个指代字段 vpred 匹配顶点 ID 和属性。对于边属性,通过指代字段 epred 匹配,其中的属性可以通过属性名获取。
(3)mask()方法可以合并两个图并且只保留两个图中都有的顶点和边,在使用时需要输人另一个图作为参数。例如,将图得到的子图作为另一个图,对图 graph 与图subGraph3 进行合并,保留两个图公共的点和边,组成新的图,并保留 graph 中点和边的属性。
(4)groupEdges()方法可以合并具有相同ID的边。groupEdges()方法将同一起点与目标点的边的属性值集合在一起,根据 merge函数,对图中多重边的属性值进行合并,保证图中对应(srcID,dstD)只有一条边。 groupEdges()方法需要重新对图数据进行分区,因为相同的边可以被分配到同一个分区,所以必须在调用 groupEdges()方法前调用 Graph.partitionBy:Graph([VD,ED])进行分区。常用的分区策略是 artitionStrategy.RandomVertexCut,表示分配相同的边到同一个分区。
数据关联聚合
关联聚合操作是图计算的重点操作,通过关联操作可以将顶点属性值连接到图中。而聚合操作可以发送信息给指定顶点并聚合数据。
用户社交网络图为例,每个用户有顶点 ID、属性 name 和 age,顶点与顶点间的关系是一个权重,介绍图常用的关联聚合操作的方法。
(1)collectNeighbors() 方法的作用是收集每个顶点的邻居顶点的顶点 ID 和顶点属性,邻居顶点就是与该点直接相连的顶点。该方法需要输入一个参数,返回的结果是顶点 ID 和顶点属性的元组。参数有以下几种类型。 ① EdgeDirection.Out:表示只收集以该顶点为起点、以邻居顶点为目标点的邻居顶点的顶点 ID 和顶点信息。 ② EdgeDirection.In:表示只收集以邻居顶点作为起点、以该点作为目标点的邻居顶点的顶点 ID 和顶点信息。 ③ EdgeDirection.Either:收集所有邻居顶点的顶点 ID 和顶点信息。 分别使用3种参数查询用户社交网络图中每个顶点的邻居顶点的顶点ID和顶点属性。
(2)collectNeighborlds() 方法的使用方式与 collectNeighbors()方法的使用方式一致,但collectNeighborlds0)方法只返回顶点 ID。
(3)aggregateMessages( 图分析任务的关键步骤之一是汇总每个顶点附近的信息。aggregateMessages()方法是Graphx 中的核心聚合操作,主要功能是向其他顶点发消息,聚合每个顶点收到的消息,返回VertexRDD[A]类型的结果,A 为某种数据类型。
在 aggregateMessages()方法中,会将用户定义的 sendMsg 函数应用到图的每个边三元 组,并对其目标点应用 mergeMsg 函数聚合数据。具体过程如下。 ① 将 sendMsg 函数看作 Hadoop 的 MapReduce 过程中的 Map 阶段,负责向邻边发消息。函数的左侧为每个边三元组,包括边的起点、目标点、属性,以及起点的属性和目标点的属性;右侧为需要发送的顶点类型以及发送的信息。对每一个三元组的起点和目标点中的至少一个顶点发送一个或多个消息,对应方法为sendToSrc()和 sendToDst()。 ② 将用户自定义的 mergeMsg 函数应用于每一个顶点,对 sendMsg 过程中发送到各顶点的数据进行合并。合并的函数的运行原理是将发送的两个消息合并为一个消息后再加入一个新的消息,与之前得到的消息进行合并,直至所有消息处理完毕。可以将mergeMsg函数看作 MapReduce 过程中的 Reduce 阶段。 ③ TripletFields 参数可指出哪些数据将被访问,有3种可选择的值,即 TripletFields.SrcTripletFields.Dst 和 TripletFields.All,分别表示源顶点特征、目标点特征和两者同时。因此TripletFields 参数的作用是通知 GraphX 仅仅需要 EdgeContext 的一部分参与计算TripletFields 是一个优化的连接策略。
(4)joinVertices joinVertices()方法用于连接其他顶点,将其他顶点的顶点信息与图中的顶点信息处理后,更新图的顶点信息。其返回值的类型是图结构顶点属性的类型,顶点个数不能新增也不可以减少,即不能改变原始图结构顶点属性的类型和个数。 将外部存放顶点的 RDD与图进行连接,对应于图结构中的某些顶点,若 RDD 中无对应的属性,则保留图结构中原有属性值,不进行任何改变。 对应于图结构中某些顶点,若 RDD 中对应的值不只一个,则只有最后一个值在进行连接操作时起作用。这种情况下,可以选择先对顶点 RDD进行处理,确保顶点不重复。
(5)outerJoinVertices() 与使用 joinVertices()方法的不同之处在于,使用 outerJoinVertices()方法后,顶点属性更新后的类型和个数可以与原先图中顶点属性的类型和个数不同。在outerJoinVertices()方法中,使用者可以随意定义想要的返回类型,从而可以完全改变图的顶点属性的类型和个数。
小结
介绍了图与图计算的基本概念,其次结合任务描述,介绍了Spark GraphX 图计算框架的基础概念和发展历程,再重点介绍 Spark GraphX基本操作,最后结合网页相关数据。
相关思维导图模板


树图思维导图提供 财务管理第十二章 融资决策 在线思维导图免费制作,点击“编辑”按钮,可对 财务管理第十二章 融资决策 进行在线思维导图编辑,本思维导图属于思维导图模板主题,文件编号是:da731f51407546c1cadcda8308ad1c91

树图思维导图提供 精细化营销 在线思维导图免费制作,点击“编辑”按钮,可对 精细化营销 进行在线思维导图编辑,本思维导图属于思维导图模板主题,文件编号是:2c4b8112404aa6081349eed61911ad55







 上海工商
上海工商