



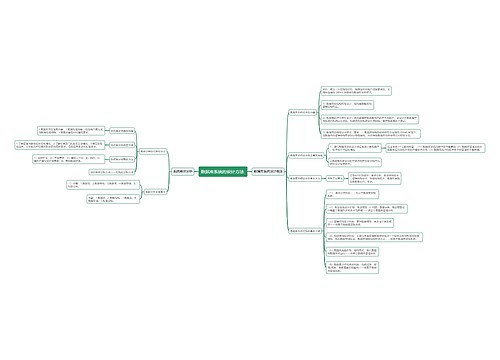
新产品数据收集流程思维导图
新产品数据收集流程内容简述
树图思维导图提供 新产品数据收集流程 在线思维导图免费制作,点击“编辑”按钮,可对 新产品数据收集流程 进行在线思维导图编辑,本思维导图属于思维导图模板主题,文件编号是:22c84bee2894f721f3f50b379c52d442
思维导图大纲
新产品数据收集流程思维导图模板大纲
离线
Hive
建库赋权
建库,角色, 这里数仓库也一起创建
PG
环境配置
确认网络是否能正常访问。如果不能访问,联系陈飞开通网络
配置linux hosts文件
工具配置修改
dataxui底层配置修改
项目地址:
conf/dataxconfig
conf/properties.py
2
dataxui工具代码发布
1. 参考迁移或者底层hostname找到dataxui部署节点
工具后台配置修改
1. 配置/数据库配置 图1
扩展选项卡配置
同步配置生成
工具后台/数据同步/任务配置
azkaban
pg-hive的配置需要配置调度运行
http://10.0.16.6/BigData/streamkar-jobs/tree/master/datax_projecthttp://10.0.16.6/BigData/streamkar-jobs/tree/master/datax_project
项目中配置新产品同步的任务flow
发布azkaban-datax_project项目
实时
CDC
1. flink提交节点 /opt/flink-process/flink-cdc-run
2. 需要dba提供 publication.name
'''示例
'''
日志
1. 找开发问程序地址
Kudu
创建kudu表
示例
CREATE TABLE kudu_tb.kimi_tshow_hist_sms_data (
添加自动range分区
配置streamsets
1. kafka-kudu模式,可以复制一个相似管道
存
由于kudu会定期滚动删除历史数据, 部分结余变更数据和日志数据需要配置脚本(一般每个产品都创建load_hive的azkaban项目)入hive存储
日志
新产品使用脚本az_job_start.py调度shell运行,需要对新库维护列表







 上海工商
上海工商