



知识库优化思维导图

性能优化,效果优化等内容讲解
树图思维导图提供 知识库优化 在线思维导图免费制作,点击“编辑”按钮,可对 知识库优化 进行在线思维导图编辑,本思维导图属于思维导图模板主题,文件编号是:bff357b9181ba2ec79cc5e1e2a22e6eb
思维导图大纲
知识库优化思维导图模板大纲
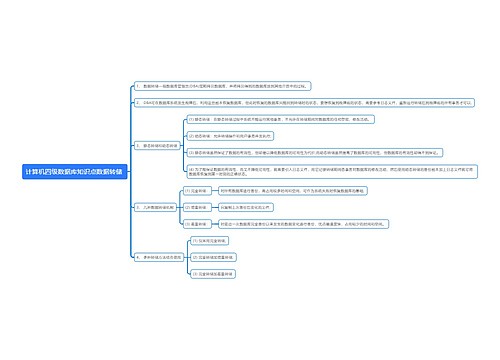
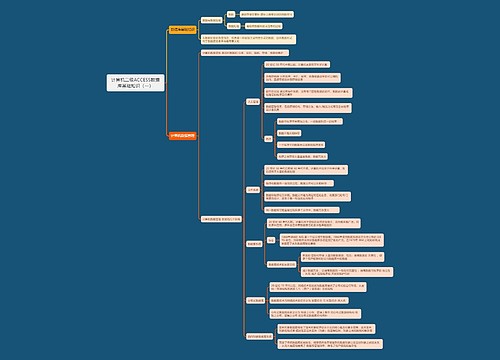
性能优化
当前的问题
当用户插入几万字文本后,由于要把文本拆分成多块,再对每块文本调用第三方embedding接口进行embedding,如果其中任何一个文本块由于网络问题导致调用接口失败,就会导致整篇文章失败。文字越多,分成的块数也越多,失败的概率也越大
优化方向
知识库的embedding使用部署在本地的bge embedding模型(中英文使用bge-m3,日语还是使用原来的embedding方法,因为bge的embedding模型在日语上效果不理想)。由于使用了部署在本地的embedding模型,就不存在网络问题导致embedding不成功的问题。(只可能是文本的编码问题才可能会导致embedding失败)
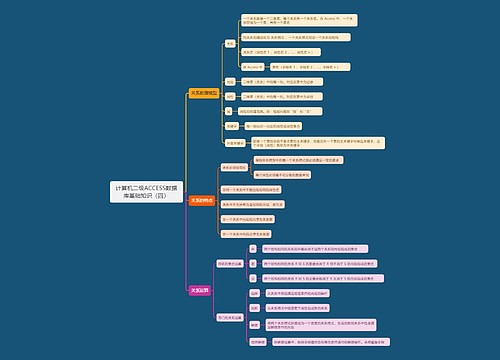
效果优化
召回效果优化
语义检索
现在的基于embedding的检索
字符串模糊匹配检索
准备使用
文章切片
试验多种切片方式
召回时候,将召回片段的前后各加一个片段一起放入召回
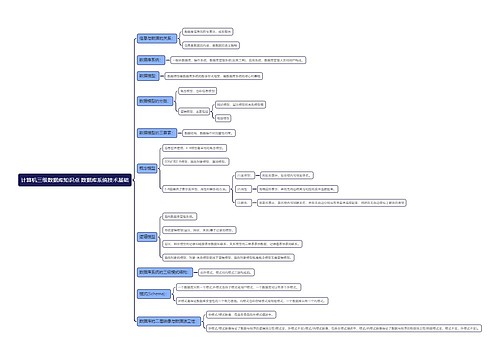
LLM生成效果优化
当前主要存在的问题
根据召回的文章片段,回答用户问题时候,会 少说、胡说
解决方法
常规方法 (微调模型)
收集少说或者乱说的文章片段、用户的问题和LLM的回答
将答案人工纠正
然后对LLM进行微调
缺点:
人工纠正和标注工作量比较大
我们面对的行业也不固定,有医疗、教育、园区等,而且每个行业的每家公司,可能对同一段文本和问题,答案也相差较大
我们自己的方法(在不同时刻选用不同的模型,尽最大程度在不同情况下选用当时最好的模型去生成)
分析现状
知识库回答是流式的,不可能等流式结束再对回答内容用后处理进行判断答案是否靠谱,这会让回答时间变慢。同理,也不可能使用非流式,也会变慢
提示词控制大模型不乱说,也有极限,天花板比较低
解决思路
语义缓存+三个臭皮匠胜过一个诸葛亮的方法
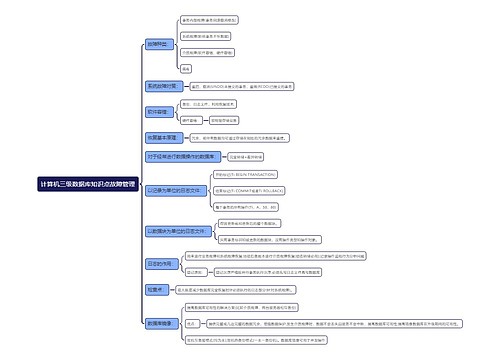
1.针对同一个uid,如果命中知识库,启用语义缓存
语义缓存的前提
对要放入语义缓存的历史答案经过一个agent过滤
判断LLM的答案与用户的问题和文章的片段是高度相关,且答案内容语法正确和语义完整,没有胡说的情况才放入语义缓存
2.准备多个大模型(这些大模型需要效果在同一个水平线,但是不是同一家的,目的是让各个大模型势均力敌,但侧重点不一样)
每次回答记录各个大模型的答案和问题以及文章片段,并离线做一个agent
离线的agent的作用
判断LLM的答案与用户的问题及文章片段的相似度,或者其他的回答质量的评分方法
得到一个相似度或者评分,后面叫评分
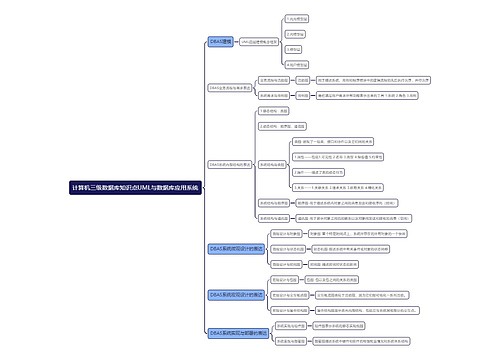
用户的问题如果命中知识库
判断是否命中语义缓存(其实判断是根据句子相似度去判断的)
命中了(相似度高于一个比较高的阈值s1)
给出答案
没命中(相似度低于那个比较高的阈值s1)
再卡一个相对低一些的阈值s2(也就是s1>s2)
当相似度大于等于s2
查看最相似的那个句子对应的答案是哪个LLM大模型生成的,就选择用那个大模型来进行本次的答案生成
当相似度小于s2
选用最近一段时间或者累计历史上,评分最高的LLM大模型进行本次的答案生成








 上海工商
上海工商