



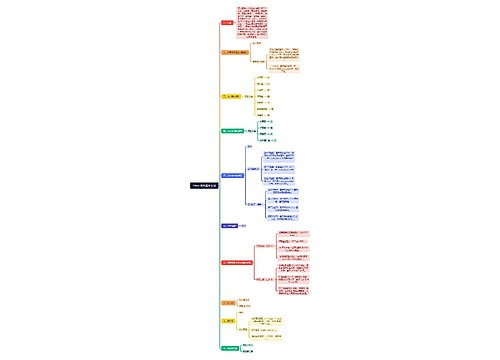
掌握Data Frame基础操作思维导图

对象创建,数据查看,数据查询等内容讲解
树图思维导图提供 掌握Data Frame基础操作 在线思维导图免费制作,点击“编辑”按钮,可对 掌握Data Frame基础操作 进行在线思维导图编辑,本思维导图属于思维导图模板主题,文件编号是:b5a407ac9d89a141553abba01202f598
思维导图大纲
掌握Data Frame基础操作思维导图模板大纲
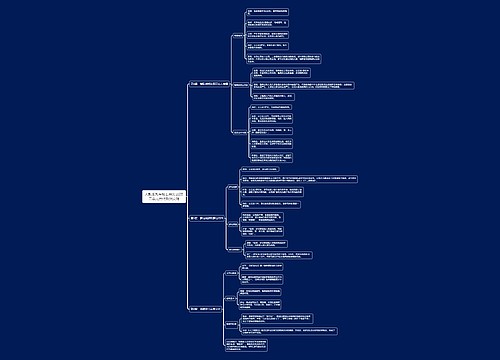
Spark SQL提供了一个抽象的编程数据模型DataFrame,DataFrame是由SchemaRDD发展而来的,从Spark 1.3.0开始,SchemaRDD更名为DataFrame。SchemaRDD直接继承自RDD,而DataFrame则自身实现RDD的绝大多数功能。 可以将Spark SQL的DataFrame理解为一个分布式的Row对象的数据集合,该数据集合提供了由列组成的详细模式信息。 本节的任务是学习DataFrame对象的创建方法及基础的操作。
创建Data Frame对象
1. 通过结构化数据文件创建DataFrame
一般情况下,结构化数据文件存储在HDFS中,较为常见的结构化数据文件是Parquet文件或JSON文件。 Spark SQL可以通过load()方法将HDFS上的结构化文件数据转换为DataFrame,load()方法默认导入的文件格式是Parquet。 若加载JSON格式的文件数据,将其转换为DataFrame,则还需要使用format()方法。 也可以直接使用json()方法将JSON文件数据转换为DataFrame。
2. 通过外部数据库创建DataFrame
Spark SQL可以从外部数据库(比如MySQL、Oracle等数据库)中创建DataFrame。 使用这种方式创建DataFrame需要通过JDBC连接或ODBC连接的方式访问数据库。 读取MySQL数据库的表数据
3. 通过RDD创建DataFrame
利用反射机制推断RDD模式,使用这种方式首先需要定义一个case class,因为只有case class才能被Spark隐式地转换为DataFrame。
4. 通过Hive中的表创建DataFrame
使用SparkSession对象并调用sql()方法查询Hive中的表数据并将其转换成DataFrame。
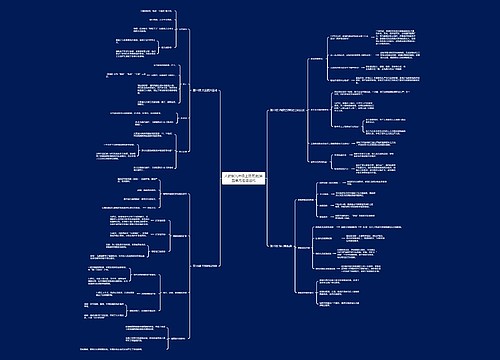
查看Data Frame数据
查看及获取数据的常用函数或方法
printSchema(打印数据模式)
printSchema函数查看数据模式,打印出列的名称和类型
show(查看数据)
show()
显示前20条记录
show(numRows:Int)
显示numRows条
show(truncate:Boolean)
是否最多只显示20个字符,默认为true
show(numRows:Int,truncate:Boolean)
显示numRows条记录并设置过长字符串的显示格式
show(true)
show()方法与show(true)方法一样,只显示前20条记录并且最多只显示20个字符 若是要显示所有字符,需要使用show(false)方法
show(numRows:Int)
查看前n行记录
first/head/take/takeAsList(获取若干行数据)
first
获取第一行记录
head(n:Int)
获取前n行记录
take(n:Int)
获取前n行记录
takeAsList(n:Int)
获取前n行数据,并以列表的形式展现
collect/collectAsList(获取所有数据)
collect方法可以将DataFrame中的所有数据都获取到,并返回一个数组。
collectAsList方法可以获取所有数据,返回一个列表。
掌握Data Frame数据查询
将DataFrame注册成为临时表,然后通过SQL语句进行查询
直接在DataFrame对象上进行查询,DataFrame提供了很多查询的方法
where
条件查询
select/selectExpr/col/apply
查询指定字段的数据信息
limit
查询前n行记录
order by
排序查询
group by
分组查询
join
连接查询
掌握Data Frame输出操作
save()方法可以将DataFrame数据保存成文件。 saveAsTable()方法可以将DataFrame数据保存成持久化的表,并在Hive的元数据库中创建一个指针指向该表的位置,持久化的表会一直保留,即使Spark程序重启也没有影响,只要连接至同一个元数据服务即可读取表数据。 读取持久化表时,只需要用表名作为参数,调用spark.table()方法方法即可得到对应DataFrame。 默认情况下,saveAsTable()方法会创建一个内部表,表数据的位置是由元数据服务控制的。如果删除表,那么表数据也会同步删除
将DataFrame数据保存为文件,步骤如下。 1.首先创建一个映射对象,用于存储save()方法需要用到的数据,这里将指定文件的头信息及文件的保存路径。 2.从user数据中选择出userId、gender和age这3列字段的数据。 3.调用save()方法将步骤中的DataFrame数据保存至copyOfUser.json文件夹中。 4.在HDFS的/user/root/sparkSql目录下查看保存结果。
使用saveAsTable()方法将DataFrame对象copyOfUser保存为copyUser表。
相关思维导图模板

树图思维导图提供 Linux 网络基础知识 在线思维导图免费制作,点击“编辑”按钮,可对 Linux 网络基础知识 进行在线思维导图编辑,本思维导图属于思维导图模板主题,文件编号是:199680f0e48eac8a1aeaadb90447d4f4

树图思维导图提供 流程化上架操作 在线思维导图免费制作,点击“编辑”按钮,可对 流程化上架操作 进行在线思维导图编辑,本思维导图属于思维导图模板主题,文件编号是:f97bd01986010350f781d05268e8f812





 上海工商
上海工商