



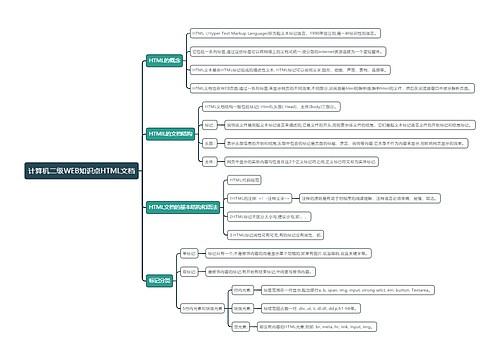
hadoop总结思维导图

hadoop总结
树图思维导图提供 hadoop总结 在线思维导图免费制作,点击“编辑”按钮,可对 hadoop总结 进行在线思维导图编辑,本思维导图属于思维导图模板主题,文件编号是:9b97036da336edee95c918967348327a
思维导图大纲
hadoop总结思维导图模板大纲
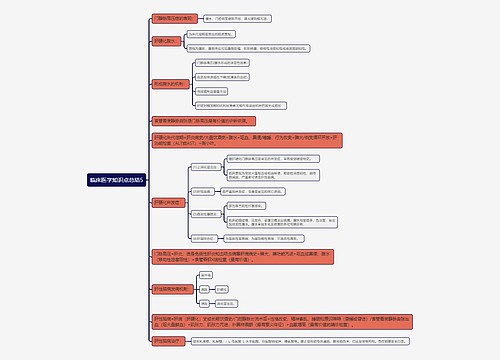
Hdfs
简介:Hadoop Distributed File System,分布式文件系统
Block数据
1、基本存储单位,一般大小为64M(配置大的块主要是因为:1)减少搜寻时间,一般硬盘传输速率比寻道时间要快,大的块可以减少寻道时间;2)减少管理块的数据开销,每个块都需要在NameNode上有对应的记录;3)对数据块进行读写,减少建立网络的连接成本)
2、一个大文件会被拆分成一个个的块,然后存储于不同的机器。如果一个文件少于Block大小,那么实际占用的空间为其文件的大小
3、基本的读写S#x5355;位,类似于磁盘的页,每次都是读写一个块
4、每个块都会被复制到多台机器,默认复制3份
NameNode
1、存储文件的metadata,运行时所有数据都保存到内存,整个HDFS可存储的文件数受限于NameNode的内存大小
2、一个Block在NameNode中对应一条记录(一般一个block占用150字节),如果是大量的小文件,会消耗大量内存。同时map task的数量是由splits来决定的,所以用MapReduce处理大量的小文件时,就会产生过多的map task,线程管理开销将会增加作业时间。处理大量小文件的速度远远小于处理同等大小的大文件的速度。因此Hadoop建议存储大文件
3、数据会定时保存到本地磁盘,但不保存block的位置信息,而是由DataNode注册时上报和运行时维护(NameNode中与DataNode相关的信息并不保存到NameNode的文件系统中,而是NameNode每次重启后,动态重建)
4、NameNode失效则整个HDFS都失效了,所以要保证NameNode的可用性
1、fsimage - 它是在NameNode启动时对整个文件系统的快照
2、edit logs - 它是在NameNode启动后,对文件系统的改动序列
Secondary NameNode
NameNode需要解决的问题
1、edit logs文件会变的很大,怎么去管理这个文件是一个挑战。
2、NameNode的重启会花费很长时间,因为有很多改动[笔者注:在edit logs中]要合并到fsimage文件上。
3、如果NameNode挂掉了,那我们就丢失了很多改动因为此时的fsimage文件非常旧。[笔者注: 笔者认为在这个情况下丢失的改动不会很多, 因为丢失的改动应该是还在内存中但是没有写到edit logs的这部分。]
Secondary NameNode职责是合并NameNode的edit logs到fsimage文件中
1、首先,它定时到NameNode去获取edit logs,并更新到fsimage上。[笔者注:Secondary NameNode自己的fsimage]
2、一旦它有了新的fsimage文件,它将其拷贝回NameNode中。
3、NameNode在下次重启时会使用这个新的fsimage文件,从而减少重启的时间。
4、Secondary NameNode的整个目的是在HDFS中提供一个检查点。它只是NameNode的一个助手节点。这也是它在社区内被认为是检查点节点的原因。
Yarn
hadoop1.*框架MapReduce
旧的MapReduce架构
1、JobTracker: 负责资源管理,跟踪资源消耗和可用性,作业生命周期管理(调度作业任务,跟踪进度,为任务提供容错)
2、TaskTracker: 加载或关闭任务,定时报告认为状态
问题
1、JobTracker是MapReduce的集中处理点,存在单点故障
2、JobTracker完成了太多的任务,造成了过多的资源消耗,当MapReduce job 非常多的时候,会造成很大的内存开销。这也是业界普遍总结出老Hadoop的MapReduce只能支持4000 节点主机的上限
3、在TaskTracker端,以map/reduce task的数目表示过于简单,没有考虑到cpu/ 内存的占用情况,如果两个大内存消耗的task被调度到了一块,很容易出现OOM
4、在TaskTracker端,把资源强制划分为map task slot和reduce task slot, 如果当系统中只有map task或者只有reduce task的时候,会造成资源的浪费,也就集群资源利用的问题
5、总的来说就是单点问题和资源利用率问题
YARN架构
职责总结
ResourceManager: 全局资源管理和任务调度
资源管理
1、以前资源是每个节点分成一个个的Map slot和Reduce slot,现在是一个个Container,每个Container可以根据需要运行ApplicationMaster、Map、Reduce或者任意的程序
2、以前的资源分配是静态的,目前是动态的,资源利用率更高
3、Container是资源申请的单位,一个资源申请格式:<resource-name, priority, resource-requirement, number-of-containers>, resource-name:主机名、机架名或*(代表任意机器), resource-requirement:目前只支持CPU和内存
4、用户提交作#x4F5C;业到ResourceManager,然后在某个NodeManager上分配一个Container来运行ApplicationMaster,ApplicationMaster再根据自身程序需要向ResourceManager申请资源
5、YARN有一套Container的生命周期管理机制,而ApplicationMaster和其Container之间的管理是应用程序自己定义的
任务调度
1、只关注资源的使用情况,根据需求合理分配资源
2、Scheluer可以根据申请的需要,在特定的机器上申请特定的资源(ApplicationMaster负责申请资源时的数据本地化的考虑,ResourceManager将尽量满足其申请需求,在指定的机器上分配Container,从而减少数据移动)
NodeManager: 单个节点的资源管理和监控, Node节点下的Container管理
1、启动时向ResourceManager注册并定时发&##x9001;心跳消息,等待ResourceManager的指令
2、监控Container的运行,维护Container的生命周期,监控Container的资源使用情况
3、启动或停止Container,管理任务运行时的依赖包(根据ApplicationMaster的需要,启动Container之前将需要的程序及其依赖包、配置文件等拷贝到本地)
ApplicationMaster: 单个作业的资源管理和任务监控
1、计算应用的资源需求,资源可以是静态或动态计算的,静态的一般是Client申请时就指定了,动态则需要ApplicationMaster根据应用的运行状态来决定
2、根据数据来申请对应位置的资源(Data Locality)
3、向ResourceManager申请资源,与NodeManager交互进行程序的运行和监控,监控申请的资源的使用情况,监控作业进度
4、跟踪任务状态和进度,定时向ResourceManager发送心跳消息,报告资源的使用情况和应用的进度信息
5、负责本作业内的任务的容错
如何计算资源需求
一般的MapReduce是根据block数量来定Map和Reduce的计算数量,然后一般的Map或Reduce就占用一个Container
如何发现数据的本地化
据本地化是通过HDFS的block分片信息获取的
Container: 资源申请的单位和任务运行的容器
1、基本的资源单位(CPU、内存等)
2、Container可以加载任意程序,而且不限于Java
3、一个Node可以包含多个Container,也可以是一个大的Container
4、ApplicationMaster可以根据需要,动态申请和释放Container
MapReduce
相关思维导图模板

树图思维导图提供 1113爆卡会总结会会议纪要 在线思维导图免费制作,点击“编辑”按钮,可对 1113爆卡会总结会会议纪要 进行在线思维导图编辑,本思维导图属于思维导图模板主题,文件编号是:aaf6c152a765d5821e8e1787f2b3226e


树图思维导图提供 总结 在线思维导图免费制作,点击“编辑”按钮,可对 总结 进行在线思维导图编辑,本思维导图属于思维导图模板主题,文件编号是:1b4116f2584ad5177f1537382a5b731f






 上海工商
上海工商