

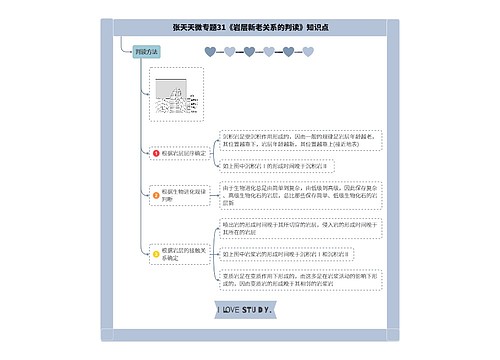
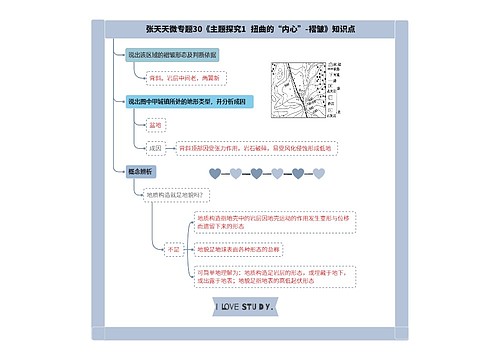
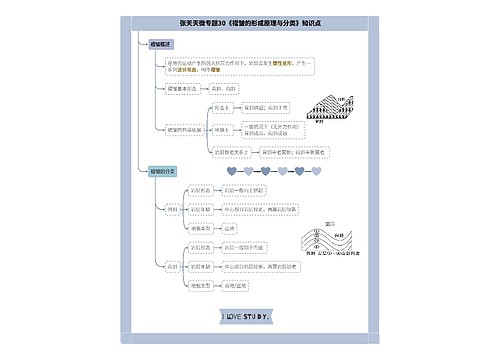
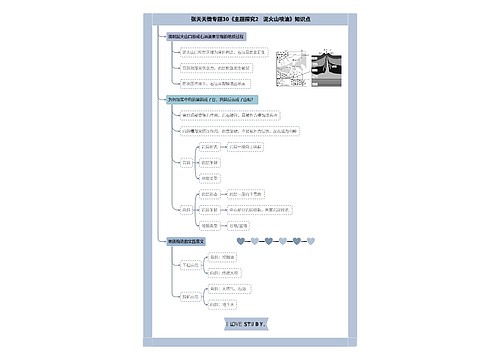
微服务集群工作总结(共3篇)思维导图
思维导图高清图")
微服务集群工作总结 第1篇为解决上述单体架构下的各种问题,微服务架构应运而生。与其构建一个臃肿庞大、难以驯服的怪兽,还不如及早将服务拆分。微服务的核心思想便是服务拆分与解耦,降低复杂性。
树图思维导图提供 微服务集群工作总结(共3篇) 在线思维导图免费制作,点击“编辑”按钮,可对 微服务集群工作总结(共3篇) 进行在线思维导图编辑,本思维导图属于思维导图模板主题,文件编号是:cb29ece2a254cb878fecf454bef3b666
思维导图大纲
微服务集群工作总结(共3篇)思维导图模板大纲
微服务集群工作总结 第1篇
为解决上述单体架构下的各种问题,微服务架构应运而生。与其构建一个臃肿庞大、难以驯服的怪兽,还不如及早将服务拆分。微服务的核心思想便是服务拆分与解耦,降低复杂性。微服务强调将功能合理拆解,尽可能保证每个服务的功能单一,按照单一责任原则(Single Responsibility Principle)明确角色。 将各个服务做轻,从而做到灵活、可复用,亦可根据各个服务自身资源需求,单独布署,单独作横向扩展。微服务的好处在于:
微服务不是万能的,更不是适用于所有场景的。在对微服务的尝试过程中,会发现某些场景下滥用或者错误设计下,也可能带你陷入灾难。
微服务集群工作总结 第2篇
微服务化后,服务变多,调用链路变长,如果一个调用链上某个服务节点出问题,很可能引发整个调用链路崩溃,也就是所谓的雪崩效应。
举个例子,详细理解一下雪崩。如上图,现在有A,B,C三个服务,A调B,B调C。假如C发生故障,B方法1调用C方法1的请求不能及时返回,B的线程会发生阻塞等待。B会在一定时间后因为线程阻塞耗尽线程池所有线程,这时B就会无法响应A的请求。A调用B的请求不能及时返回,A的线程池线程资源也会逐渐被耗尽,最终A也无法对外提供服务。这样就引发了连锁故障,发生了雪崩。纵向:C故障引发B故障,B故障引发A故障,最终发生连锁故障。横向:方法1出问题,导致线程阻塞,进而线程池线程资源耗尽,最终服务内所有方法都无法访问,这就是"线程池污染"
为了避免雪崩效应,我们可以从两个方面考虑:
常用开源熔断隔离组件:Hystrix,Resilience4j
可以从全局,IP,userID等多维度做限流。限流的两个主要目的:1,应对突发流量,避免系统被压垮(全局限流和IP限流)2,防刷,防止机器人脚本等频繁调用服务(userID限流和IP限流)
在核心链路上,服务可以冗余它依赖的服务的数据,依赖的服务故障时,服务尽量做到自保。比如订单服务依赖库存服务。我们可以在订单服务冗余库存数据(注意控制合理的安全库存,防超卖)。下单减库存时,如果库存服务挂了,我们可以直接从订单服务取库存。可以结合熔断一起使用,作为熔断的Fallback(后备)方案。
可能很多人都听过服务降级,但是又不知道降级是怎么回事。实际上,上面说的熔断,限流,数据冗余,都属于服务降级的范畴。还有手动降级的例子,比如大促期间我们会关掉第三方物流接口,页面上也关掉物流查询功能,避免拖垮自己的服务。这种降级的例子很多。不管什么降级方式,目的都是让系统可用性更高,容错能力更强,更稳定。关于服务降级详见本文后面的内容。
缓存穿透。对于数据库中根本不存在的值,请求缓存时要在缓存记录一个空值,避免每次请求都打到数据库
缓存雪崩。在某一时间缓存数据集中失效,导致大量请求穿透到数据库,将数据库压垮。可以在初始化数据时,差异化各个key的缓存失效时间,失效时间 = 一个较大的固定值 + 较小的随机值
缓存热点。有些热点数据访问量会特别大,单个缓存节点(例如Redis)无法支撑这么大的访问量。如果是读请求访问量大,可以考虑读写分离,一主多从的方案,用从节点分摊读流量;如果是写请求访问量大,可以采用集群分片方案,用分片分摊写流量。以秒杀扣减库存为例,假如秒杀库存是100,可以分成5片,每片存20个库存。
部署隔离:我们经常会遇到秒杀业务和日常业务依赖同一个服务,以及C端服务和内部运营系统依赖同一个服务的情况,比如说都依赖订单服务。而秒杀系统的瞬间访问量很高,可能会对服务带来巨大的压力,甚至压垮服务。内部运营系统也经常有批量数据导出的操作,同样会给服务带来一定的压力。这些都是不稳定因素。所以我们可以将这些共同依赖的服务分组部署,不同的分组服务于不同的业务,避免相互干扰。
数据隔离:极端情况下还需要缓存隔离,数据库隔离。以秒杀为例,库存和订单的缓存(Redis)和数据库需要单独部署!数据隔离后,秒杀订单和日常订单不在相同的数据库,之后的订单查询怎么展示?可以采用相应的数据同步策略。比如,在创建秒杀订单后发消息到消息队列,日常订单服务收到消息后将订单写入日常订单库。注意,要考虑数据的一致性,可以使用事务型消息。
业务隔离:还是以秒杀为例。从业务上把秒杀和日常的售卖区分开来,把秒杀做为营销活动,要参与秒杀的商品需要提前报名参加活动,这样我们就能提前知道哪些商家哪些商品要参与秒杀,可以根据提报的商品提前生成商品详情静态页面并上传到CDN预热,提报的商品库存也需要提前预热,可以将商品库存在活动开始前预热到Redis,避免秒杀开始后大量访问穿透到数据库。
CI测试,持续集成测试,在我们每次提交代码到发布分支前自动构建项目并执行所有测试用例,如果有测试用例执行失败,拒绝将代码合并到发布分支,本次集成失败。CI测试可以保证上线质量,适用于用例不会经常变化的稳定业务。
性能测试,为了保证上线性能,所有用户侧功能需要进行性能测试。上线前要保证性能测试通过。而且要定期做全链路压测,有性能问题可以及时发现。
微服务集群工作总结 第3篇
老库和新库同时写入,然后将老数据批量迁移到新库,最后流量切换到新库并关闭老库读写。
以笔者之前经历的用户系统重构为例,聊一下具体方案。当时的场景是这样的,用户表记录数达到3000万时,系统性能和可维护性变差,于是我们将用户中心从单体工程中拆分出来并做了重构,重新设计了表结构,而且业务方要求不停机上线!就需要注意下面是我们当时的方案,步骤如下:
代码准备。在服务层对用户表进行增删改的地方,要同时操作新库和老库,需要修改相应的代码(同时写新库和老库)。准备迁移程序脚本,用于做老数据迁移。准备校验程序脚本,用于校验新库和老库的数据是否一致。
对于第一种微服务场景,新库可以是一个单独的数据库,对于第二种场景新库就是一个已经搭建好具备分片功能的数据库。
开启双写,老库和新库同时写入。注意:任何对数据库的增删改都要双写;对于更新操作,如果新库没有相关记录,需要先从老库查出记录,将更新后的记录写入新库,如果新库有记录则新库老库一起更新;对于删除操作,如果新库没有数据则删除老库数据即可,如果新库有数据则新库老库一起删除。对于新增操作则保证新库和老库都新增成功。为了保证写入性能,老库写完后,可以采用消息队列异步写入新库。注意:双写的操作,需要保证数据的id(主键也要相同),比如老库新增老一条id为100的数据,那么在新库中这条数据的id(主键)也是100。
利用脚本程序,将某一时间戳之前的老数据迁移到新库。注意:1,时间戳一定要选择开启双写后的时间点(比如开启双写后10分钟的时间点),避免部分老数据被漏掉;2,迁移过程遇到记录冲突直接忽略,产生冲突的原因可能是迁移迁移之前老库的数据已经存在于新库了(存在主键冲突的时间段就是双写开始时间到迁移老数据开始时间,这段时间新库已经存在了老库的一些数据),当迁移操作开始后在往新库插入相同数据将会报主键冲突等问题;3,迁移过程一定要记录日志,尤其是错误日志,如果有双写失败的情况,我们可以通过日志恢复数据,以此来保证新老库的数据一致。4.老表迁移到新表的数据的主键Id也一定要一致,比如老表的数据Id为100,那么这条数据迁移到新表的id也应该为100
第3步完成后,我们还需要通过脚本程序检验数据,看新库数据是否准确以及有没有漏掉的数据对比办法:读取所有字段,根据字段名称+字段值进行拼接,拼接MD5是否相同,相同则不追究,不相同用原表进行覆盖
数据校验没问题后,开启双读,起初给新库放少部分流量,新库和老库同时读取。由于延时问题,新库和老库可能会有少量数据记录不一致的情况,所以新库读不到时需要再读一遍老库。逐步将读流量切到新库,相当于灰度上线的过程。遇到问题可以及时把流量切回老库
读流量全部切到新库后,关闭老库写入(可以在代码里加上热配置开关),只写新库
迁移完成,后续可以去掉双写双读相关无用代码。
切回单写及数据表rename当切换的新表和老表属于同一个库时,这里最好进行rename操作,也就是新表rename成老表。好处:如果老表的数据来自上游写入,那么我只需要将新表rename为老表即可,上游表对应不需要更新了。坏处:这个操作需要dba进行,且rename期间服务不可用
目前各云服务平台也提供数据迁移解决方案,大家有兴趣也可以了解一下!
全链路APM监控
在体会到微服务带来好处的同时,很多公司也会明显感受到微服务化后那些让人头疼的问题。比如,服务化之后调用链路变长,排查性能问题可能要跨多个服务,定位问题更加困难;服务变多,服务间调用关系错综复杂,以至于很多工程师不清楚服务间的依赖和调用关系,之后的系统维护过程也会更加艰巨。诸如此类的问题还很多!
这时就迫切需要一个工具帮我们解决这些问题,于是APM全链路监控工具就应运而生了。有开源的Pinpoint、Skywalking等,也有收费的Saas服务听云、OneAPM等。有些实力雄厚的公司也会自研APM。
下面我们介绍一下如何利用开源APM工具Pinpoint应对上述问题。
拓扑图
微服务化后,服务数量变多,服务间调用关系也变得更复杂,以至于很多工程师不清楚服务间的依赖和调用关系,给系统维护带来很多困难。通过拓扑图我们可以清晰地看到服务与服务,服务与数据库,服务与缓存中间件的调用和依赖关系。对服务关系了如指掌之后,也可以避免服务间循依赖、循环调用的问题。
请求调用栈(Call Stack)监控
相关思维导图模板

树图思维导图提供 1113爆卡会总结会会议纪要 在线思维导图免费制作,点击“编辑”按钮,可对 1113爆卡会总结会会议纪要 进行在线思维导图编辑,本思维导图属于思维导图模板主题,文件编号是:aaf6c152a765d5821e8e1787f2b3226e

树图思维导图提供 3A Unit 1 A Proper Job 在线思维导图免费制作,点击“编辑”按钮,可对 3A Unit 1 A Proper Job 进行在线思维导图编辑,本思维导图属于思维导图模板主题,文件编号是:8d966446cda22e33b426cba15d3d981e









 上海工商
上海工商