

机器学习数据科学库脑图思维导图

机器学习数据科学库的分类和相关理论说明脑图
树图思维导图提供 机器学习数据科学库脑图 在线思维导图免费制作,点击“编辑”按钮,可对 机器学习数据科学库脑图 进行在线思维导图编辑,本思维导图属于思维导图模板主题,文件编号是:5548b5a32ec4435f1cb28b377399184c
思维导图大纲
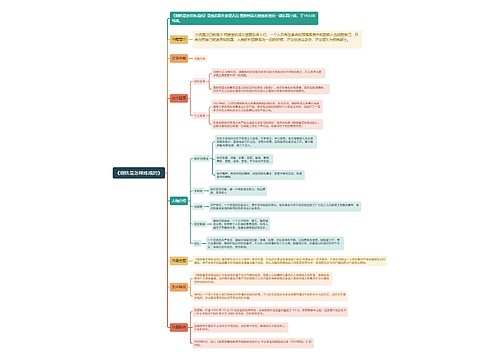
机器学习(数据科学库)思维导图模板大纲
人工智能概述
人工智能必备三要素
数据
算法
计算力
cpu和gpu的区别
CPU:IO密集型
GPU:计算密集型
人工智能主要分支
知识图谱
语音识别
人脸识别
用户画像
机器学习
定义
是从数据中自动分析,获得模型,并利用模型对未知数据进行分析
流程
1.获取数据
2.数据基本处理
3.特征工程
4.机器学习(模型训练)
5.模型评估
ps:一定阅读课件中拓展内容
获取数据
有目标值的数据
没有目标值的数据
数据基本处理
对数进行缺失值、去除异常值等处理
特征工程
特征提取
特征预处理
特征降维
机器学习算法
监督学习
回归问题
分类问题
无监督 学习
半监督学习
强化学习
模型评估
分类评估
准确率
精确率
召回率
回归评估
均方误差(MSE)
均方根误差(RMSE)
平方绝对误差(MAE)
拟合
欠拟合
过拟合
深度学习
仿神经元构造的神经网络层
前面层识别简单的东西
后面层识别比较复杂的内容
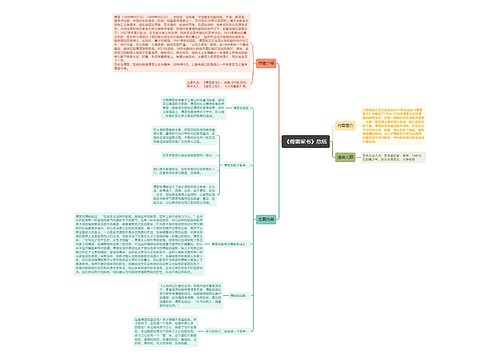
Matplotlib
简介
专门用于开发2d图表
以渐进、交互式方式实现数据可视化
绘制流程
1.创建画布
2.绘制
3.显示
各种图像
折线图
plt.plot()
能够显示数据的变化趋势,反映事物的变化情况。(变化)
散点图
plt.scatter()
判断变量之间是否存在数量关联趋势,展示离群点(分布规律)
柱状图
plt.bar()
绘制离散的数据,能够一眼看出各个数据的大小,比较数据之间的差别。(统计/对比)
直方图
plt.hist()
绘制连续性的数据展示一组或者多组数据的分布状况(统计)
饼图
plt.pie()
分类数据的占比情况(占比)
辅助功能
保存
plt.savefig("")
注意:一定要在释放之前进行保存
添加自定义x,y刻度
plt.xticks(x, label)
plt.yticks(y, label)
添加网格显示
plt.grid(True, linestyle='--', alpha=0.5)
添加描述信息
plt.xlabel()
plt.ylabel()
plt.title()
多次plot
其实就是再次对新的数据进行绘制(plot)
图例展示
plt.legend()
在plot(label="")
添加多个绘图区
pyplot.subplots(nrows=1, ncols=1)
返回对象: img对象;axes绘图区
numpy
Numpy介绍
是一个开源的Python科学计算库
用于快速处理任意维度的数组
Numpy使用ndarray对象来处理多维数组
ndarray的优势
1.内存块风格
2.ndarray支持并行化运算(向量化运算)
3.Numpy底层使用C语言编写,内部解除了GIL
N维数组-ndarray
1.ndarray的属性
ndarray.shape 数组维度的元组[***]
ndarray.ndim 数组维数
ndarray.size 数组中的元素数量
ndarray.itemsize 一个数组元素的长度(字节)
ndarray.dtype 数组元素的类型[*]
2 ndarray的形状
0维 ()
1维 (*,)
2维 (*,*)
...
基本操作
生成数组的方法
生成0和1的数组
np.ones([,])
np.zeros([,])
从现有数组生成
np.array()
np.asarray()
生成固定范围的数组
np.linspace(start, stop, num)
np.arange(start, stop, step)
生成随机数组
均匀分布
np.random.uniform(low, high, size)
正态分布[****]
np.random.normal(loc, scale, size)
形状修改
ndarray.T
ndarray.reshape([]) 产生新的对象
ndarray.resize([]) 对自身进行改变
数组去重
np.unique(temp)
运算
逻辑运算
通用判断函数
np.all() -- 所有满足要求,返回true
np.any() -- 有一个满足要求,返回true
三元运算符
np.where(temp>0,1,0)
统计运算
np.min()
np.max()
np.median()
np.mean()
np.std()
np.var()
np.argmax() -- 返回最大值所在的索引
np.argmin() -- 返回最小值所在的索引
数组间运算
数组与数的运算
数组与数组的运算 --广播机制
维度相等
shape(其中相对应的一个地方为1)
矩阵运算
(m行, n列)*(n行, l列) = (m行, l列)
np.matmul()
矩阵和矩阵相乘
np.dot()
也可以矩阵和标量相乘
pandas
Pandas介绍
结合了numpy 和 matplotlib的优势
专门用于数据挖掘的开源python库
三种结构
series
1.创建
pd.Series(np.arange())
pd.Series([], index=[])
pd.Series({})
2.属性
index
values
DataFrame
1.创建
pd.DataFrame()
index= -- 行索引
columns = -- 列索引
2.属性
1. shape -- 形状
2. index -- 行索引
3. columns -- 列索引
4. values -- 查看值(ndarray)
5. T -- 转置
6. head() -- 前几行
7. tail() -- 后几行
3.DataFrame索引的设置
设置索引,必须要全部索引进行设置,不能只修改单个
重设索引-- df.reset_index(drop=False)
设置新的索引 -- df.set_index("")
multIIndex, panel
1. multiIndex
把dataframe进行整合
df.index
df.index.names
2. panel
三维数组,特殊处理的原始版本
panel[:,:,""]
基本数据操作
1.索引操作
data[][]
data.loc[]
data.iloc[]
2.赋值
data[""] = **
data.close = **
3.排序
dataframe
df.sort_values(by="", ascending=)
df.sort_index(ascending=)
series
df[""].sort_values()
df[""].sort_index()
运算
算术运算
df[""].add()
df[""].sub()
...
逻辑运算
符号
df.query()
df[df[""].isin([])]
统计运算
describe
sum()
min()
...
idxmax()
idxmin()
累积统计函数
cumsum()
cummax()
cummin()
cumprod()
自定义函数
df.apply(func, axis=0)
文件读取与存储
1 csv
pd.read_csv("", usecols=[])
df.to_csv("", columns=[], index=, mode=, header=)
2 hdf
pd.read_hdf("", key="")
df.to_hdf("**.h5", key="")
优势:
1.读取速度快
2.提升磁盘利用率,节省空间
3.跨平台
3 json
pd.read_json()
df.to_json()
4.excel
pd.read_excel()
df.to_excel()
5.sql
pd.read_sql()
df.to_sql()
注意:首先需要创建引擎,链接成功之后,再进行相应的操作。
高级处理
缺失值
判断
np.any(pd.isnull(movie))
里面如果有一个缺失值,就返回True
np.all(pd.notnull(movie))
里面如果有一个缺失值,就返回False
处理方式
删除
df.dropna()
替换
df[i].fillna(value=movie[i].mean(), inplace=True)
特殊符号表示缺失值
df.replace(to_replace="?", value=np.NaN)
离散化
cut,qcut
get_dummies
合并
pd.concat([数据1, 数据2], axis=**)
pd.merge(left, right, how=, on=)
how -- 以何种方式连接
on -- 连接的键的依据是哪几个
交叉表与透视表
pd.crosstab(value1, value2)
data.pivot_table()
分组聚合
对象.groupby(key, as_index=False)
注意:抛开聚合,只谈分组,就是耍流氓,没有意义(只会返回一个对象
seaborn
SEaborn介绍
基于 Matplotlib核心库进行了更高级的API封装
配色更加舒服,以及图形元素的样式更加细腻
绘制单变量分布
seaborn.distplot()
(1) a:表示要观察的数据,可以是 Series、一维数组或列表。
(2) bins:用于控制条形的数量。
(3) hist:接收布尔类型,表示是否绘制(标注)直方图。
(4) kde:接收布尔类型,表示是否绘制高斯核密度估计曲线。
(5) rug:接收布尔类型,表示是否在支持的轴方向上绘制rugplot。
绘制双变量分布
seaborn.jointplot()
1) kind:表示绘制图形的类型。
scatter:散点图
hex:二维直方图
kde:核密度估计图
(2) stat_func:用于计算有关关系的统计量并标注图。
(3) color:表示绘图元素的颜色。
(4) size:用于设置图的大小(正方形)。
(5) ratio:表示中心图与侧边图的比例。该参数的值越大,则中心图的占比会越大。
(6) space:用于设置中心图与侧边图的间隔大小。
绘制成对双变量
seaborn.pairplot()
分类数据绘图
分类数据散点图
sns.stripplot()
sns.swarmplot()
分类数据的分布图
sns.boxplot()
箱线图
sns.violinplot()
小提琴图
分类数据的估算图
sns.barplot()
条形图
sns.pointplot()
点图
相关思维导图模板

树图思维导图提供 一、研究内容 在线思维导图免费制作,点击“编辑”按钮,可对 一、研究内容 进行在线思维导图编辑,本思维导图属于思维导图模板主题,文件编号是:4f21797dd3e8b08f1951dfc24e7be94f

树图思维导图提供 1113爆卡会总结会会议纪要 在线思维导图免费制作,点击“编辑”按钮,可对 1113爆卡会总结会会议纪要 进行在线思维导图编辑,本思维导图属于思维导图模板主题,文件编号是:aaf6c152a765d5821e8e1787f2b3226e







 上海工商
上海工商