

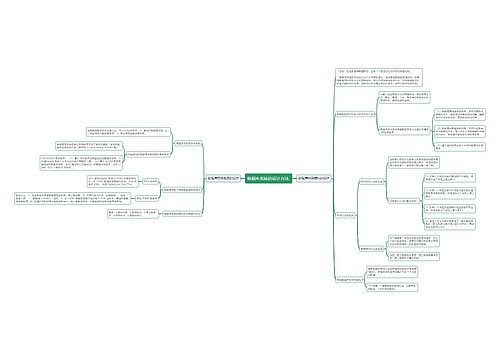
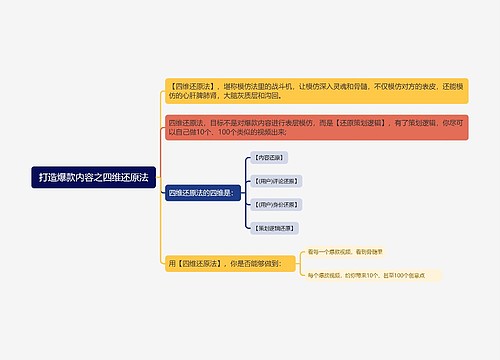
线性回归统计分析方法脑图思维导图

用线性函数对自变量(特征)和因变量之间的关系进行建模的内容详解
树图思维导图提供 线性回归统计分析方法脑图 在线思维导图免费制作,点击“编辑”按钮,可对 线性回归统计分析方法脑图 进行在线思维导图编辑,本思维导图属于思维导图模板主题,文件编号是:42a9a1a59b8b93607896a5d819890259
思维导图大纲
线性回归-07思维导图模板大纲
简介
定义
利用回归方程(函数)对一个或多个自变量(特征值)和因变量(目标值)之间关系进行建模的一种分析方式
通用公式
按照自变量个数分类
- 单变量回归: 只有一个自变量(特征值)
- 多元回归: 有多个自变量
按线性回归模型与目标关系
- 线性回归
- 非线性回归
API
sklearn.linear_model.LinearRegression()
- 方法:
- 训练: fit(x_train, y_train)
- 预测: predict(x_test)
- 属性:
- 模型系数: coef_
线性回归的损失和优化
损失
最小二乘法: (预测值-真实值)的平方求和
优化
定义: 求解损失函数最小值
两种方式:
1. 正规方程
缺点
- 计算量很大
- 当样本数量很大时候, 很难求解
2. 梯度下降
梯度
- 如果是单变量, 这一点切线斜率
- 如果是多变量, 就是这个点偏导数,
- 是有方向的, 它方向就是函数上升最快的方向
关键点
梯度下降公式
- α: 学习率(步长). 不能太大 也 不能太小.
- 梯度乘以负号的原因: 梯度是上升最快的方向, 我们需要是下降最快的方向, 所以需要加 负号
梯度下降与正规方程对比
梯度下降 正规方程 - 需要选择学习率 不需要 - 迭代求解 一次求解 - 特征数量较大可用 需要计算方程, 时间复杂度很高, 求解很慢.
选择
1. 小规模数据
1. 正规方程: LinearRegression
2. 岭回归: Ridge
2. 大规模数据
1. 梯度下降: SGDRegressor
梯度下降法介绍
- 全梯度下降算法(FGD)
- 每次迭代的时候, 都代入所有的样本计算损失求和求平均值, 作为目标函数
- 随机梯度下降算法(SGD)
- 每次迭代的时候, 只随机选择一个样本计算损失, 作为目标函数
- 小批量梯度下降算法(mini-bantch)
- 每次迭代的时候, 随机选择一个小批量的数据集, 使用FG对小批量的数据集进行梯度下降
- 随机平均梯度下降算法(SAG)
- 每次迭代的时候, 只随机选择一个样本计算损失, 每次计算梯度都存储在内存中, 在更新θ值时候, 求解所有梯度均值, 更新θ值.
结论(扩展)
1)FG方法由于它每轮更新都要使用全体数据集,故花费的时间成本最多,内存存储最大。
(2)SAG在训练初期表现不佳,优化速度较慢。这是因为我们常将初始梯度设为0,而SAG每轮梯度更新都结合了上一轮梯度值。
(3)综合考虑迭代次数和运行时间,SG表现性能都很好,能在训练初期快速摆脱初始梯度值,快速将平均损失函数降到很低。但要注意,在使用SG方法时要慎重选择步长,否则容易错过最优解。
(4)mini-batch结合了SG的“胆大”和FG的“心细”,从6幅图像来看,它的表现也正好居于SG和FG二者之间。在目前的机器学习领域,mini-batch是使用最多的梯度下降算法,正是因为它避开了FG运算效率低成本大和SG收敛效果不稳定的缺点
案例: 正规方程
API
sklearn.linear_model.LinearRegression(fit_intercept=True)
- 参数:
- fit_intercept: 是否计算偏置, 默认是True
- 属性:
- 模型系数: coef
- 模型偏置: intercept_
回归模型评估
均方误差
API
sklearn.metrics.mean_squared_error(y_true, y_pred)
- y_true: 真实的目标值
- y_pred: 预测的目标值
案例:梯度下降
API
sklearn.linear_model.SGDRegressor(loss="squared_loss", fit_intercept=True, learning_rate ='invscaling', eta0=0.01)
- fit_intercept: 是否计算偏置
- learning_rate: 学习率, 默认学习率的初始值是0.01, 每次迭代学习率都会减小. 如果指定就contant就是固定学率
- eta0: 初始学习率, 默认值 0.01
属性
- coef_: 模型系数
- intercept_: 模型偏置
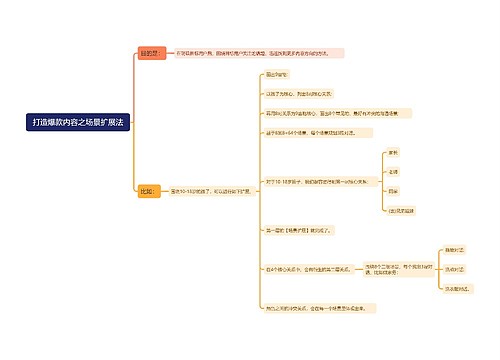
欠拟合和过拟合
欠拟合
- 概念: 训练误差大, 测试误差也大
- 原因: 模型太简单了, 学到的东西太少了
- 解决:
- 添加特征项
- 添加多项式(增加二次项或三次项)
过拟合
- 概念: 训练误差小, 测试误差大
- 原因: 模型太复杂了, 学到东西太多
- 解决:
- 清洗数据, 去掉噪声, 让数据更纯
- 增大样本数量
- 正则化
- 减少特征维度(特征降维), 防止维灾难.
正则化
解决过拟合问题
- L2正则化
- 作用 可以让一些系数变得很小, 削弱这个特征项影响. 从而让模型变得简单
- L1正则化:
- 作用: 直接让一些系数为0, 就相当于删除特征的影响; 让模型变简单了, 不容易过拟合
维灾难
随着维度的增加,分类器性能逐步上升,到达某点之后,其性能便逐渐下降
正则化与线性模型
- 岭回归(L2正则化):
- 在损失函数上 + L2正则化项
- L2正则化项: 系数的平方和
- 作用: 让一些θ变的很小, 接近于0, 从而削弱这些特征的影响
- Lasso回归(L1正则化):
- 在损失函数上 + L1正则化项
- L1正则化项: 系数绝对值的和
- 作用: 让一些θ值直接为0, 从而删除这些特征影响.
- Elastic Net 弹性网络[了解]
- 是岭回归 和 Lasso回归的折中表示
- Early Stopping[了解]
- 当损失达到可以接受的最小值的时候, 就停止训练
岭回归
- API:
- sklearn.linear_model.Ridge(alpha=1.0)
- alpha: 正则化力度
- 正则化力度与系数之间的关系
- 正则化力度越大, 模型系数越小
- 正则化力度越小, 模型系数越大
- 岭回归与线性回归的区别
- 岭回归就是在线性回归上损失函数上添加L2的正则化项
- 岭回归使用随机平均梯度下降法
- 岭回归是一种线性回归
- 总结: 岭回归是使用随机平均梯度下降法, 带有L2正则化的线性回归.
- SGDRegressor 与 Ridge区别
- SGDRegressor
- 随机梯度下降法
- Ridge
- 随机平均梯度下降法
- 使用L2正则化项.
模型保存和加载
from sklearn.externals import joblib
import joblib (0.23.0版本以上)
API:
- 保存模型: joblib.dump(estimator, '路径')
- 加载模型: joblib.load('路径')
- 注意: 文件名的后缀是 pkl
相关思维导图模板

树图思维导图提供 904名中国成年人第三磨牙相关知识、态度、行为和病史的横断面调查 在线思维导图免费制作,点击“编辑”按钮,可对 904名中国成年人第三磨牙相关知识、态度、行为和病史的横断面调查 进行在线思维导图编辑,本思维导图属于思维导图模板主题,文件编号是:10b9a8a2dd2fb4593f8130ef16c320fc

树图思维导图提供 抓住重点 在线思维导图免费制作,点击“编辑”按钮,可对 抓住重点 进行在线思维导图编辑,本思维导图属于思维导图模板主题,文件编号是:4c49e4799ddf94a339c56e46eb96a826
相关思维导图专辑






Copyright©2022-2025 树图网shutu.cn 版权所有|上海聚石塔网络科技有限公司|网站备案号:沪ICP备2021036420号-3|![]() 沪公网安备 31011502019485号|
沪公网安备 31011502019485号| 上海工商
上海工商